The heart of the machine column
Machine zhixin editorial department
Recently, researchers from monash university in Australia, ant group, IBM research institute and other institutions have explored the application of model reprogramming in large language models (LLMs). It also puts forward a brand-new perspective: efficiently reprogramming the large language model for general time series prediction-its proposed Time-LLM framework can realize high-precision time series prediction without modifying the language model, surpassing the traditional time series model in multiple data sets and prediction tasks, and making LLMs perform well in dealing with cross-modal time series data, just like an elephant dancing!

Recently, inspired by the big language model in the field of general intelligence, the new direction of "big model+time series/spatio-temporal data" has made a lot of relevant progress in generate. At present, LLMs has the potential to completely change the way of time series/spatio-temporal data mining, thus promoting the efficient decision-making of typical complex systems such as cities, energy, transportation and remote sensing, and moving towards a more universal intelligent form of time series/spatio-temporal analysis.
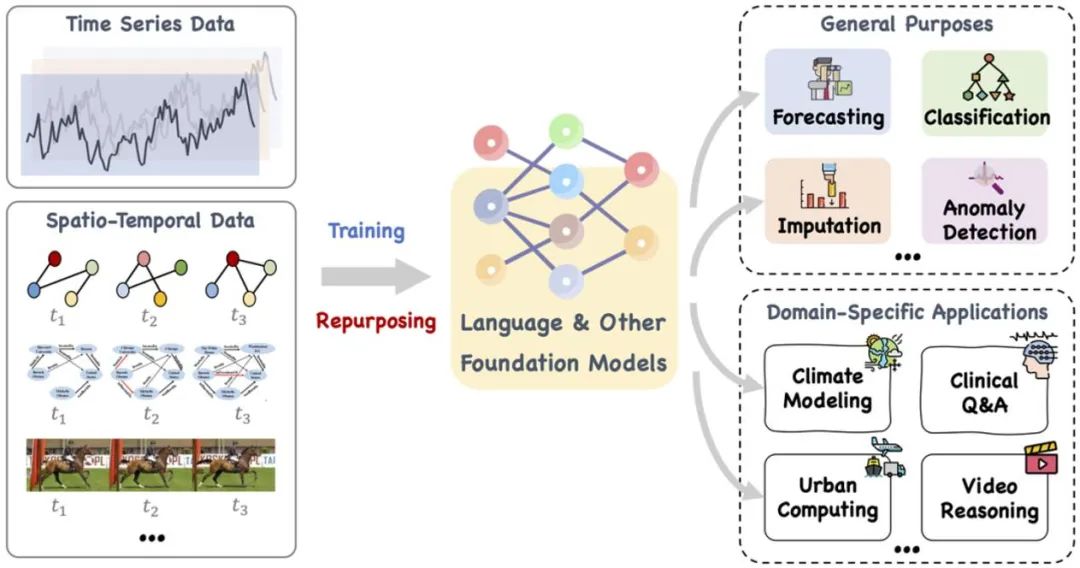
Large-scale models, such as language and other related basic models, can be trained and skillfully readjusted to deal with time series and spatio-temporal data in a series of general tasks and applications in special fields. Source: https://arxiv.org/pdf/2310.10196.pdf.
Recent studies have expanded large-scale language models from dealing with natural languages to time series and spatio-temporal tasks. This new research direction, that is, "large model+time series/spatio-temporal data", has given birth to many related developments, such as LLMTime directly using LLMs for zero-sample time series prediction and reasoning. Although LLMs has powerful learning and presentation ability, and can effectively capture complex patterns and long-term dependencies in text sequence data, as a "black box" focusing on natural language, its application in time series and spatio-temporal tasks still faces challenges. Compared with traditional time series models such as TimesNet and TimeMixer, LLMs can be compared with "elephant" for its huge parameters and scale.
Therefore, how to "tame" LLMs, which is trained in the field of natural language, so that it can process numerical sequence data across text patterns and exert its powerful reasoning and prediction ability in time series and spatio-temporal tasks has become the key focus of current research. Therefore, a deeper theoretical analysis is needed to explore the potential pattern similarity between language and time series data, and effectively apply it to specific time series and spatio-temporal tasks.
This paper expounds how to make general time series prediction by reprogramming LLM Reprogramming. It puts forward two key technologies, namely, (1) reprogramming the time sequence input and (2) prefixing the prompt, which transforms the time sequence prediction task into a "language" task that can be effectively solved by LLMs, and successfully activates the ability of large language model to do high-precision time sequence reasoning.

Address: https://openreview.net/pdf?. id=Unb5CVPtae
Paper code: https://github.com/KimMeen/Time-LLM.
1. Background of the problem
Time series data exist widely in reality, among which time series prediction is of great significance in many dynamic systems in the real world and has been widely studied. Different from natural language processing (NLP) and computer vision (CV), a single large-scale model can handle multiple tasks, and the time series prediction model often needs to be specially designed to meet the needs of different tasks and application scenarios. Although the basic model based on pre-training has made great progress in NLP and CV fields, its development in time series field is still limited by data sparsity. Recent research shows that large language models (LLMs) have reliable pattern recognition and reasoning ability when dealing with complex tag sequences. However, how to effectively align the two modes of time series data and natural language, and how to use the reasoning ability of large language model itself to deal with the task of time series analysis is still a challenge.
2. Overview of the paper
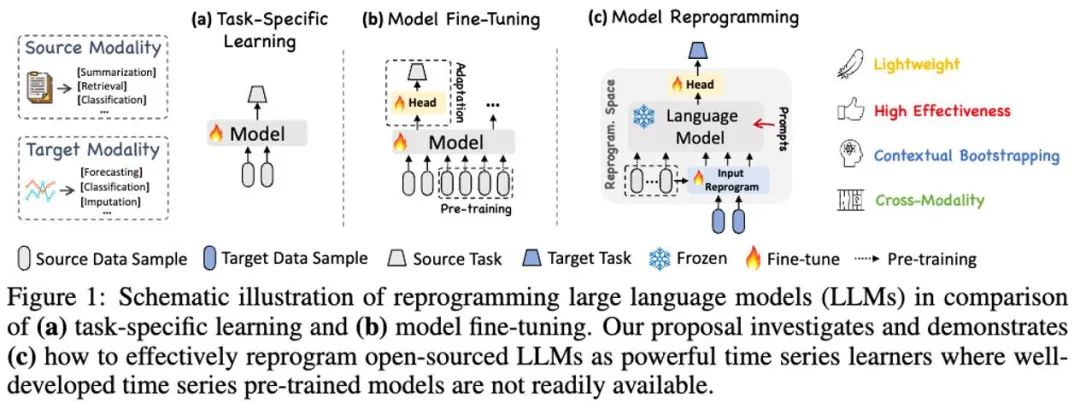
In this work, the author puts forward Time-LLM, which is a general framework of LLM Reprogramming. LLM can be easily used for general time series prediction without any training for the large language model itself. Time-LLM first reprogrammed the input time series data with Text Prototypes, and expressed the semantic information of the time series data by using natural language representation, and then aligned two different data modes, so that the large language model could understand the information behind the other data mode without any modification.
In order to further enhance LLM’s understanding of input time-series data and corresponding tasks, the author puts forward a paradigm of Prompt-as-Prefix (PaP), which fully activates LLM’s processing ability in time-series tasks by adding additional context prompts and task instructions before time-series data representation. In this work, the author has carried out sufficient experiments on the mainstream time series benchmark data sets, and the results show that Time-LLM can surpass the traditional time series model in most cases, and has greatly improved the learning tasks of Few-shot and Zero-shot.
The main contributions in this work can be summarized as follows:
1. This work puts forward a new concept of time series analysis by reprogramming large language model, without any modification to the main language model. The author shows that time series prediction can be regarded as another "language" task that can be effectively solved by ready-made LLM.
2. This work puts forward a general language model reprogramming framework, namely Time-LLM, which includes reprogramming the input time series data into a more natural text prototype representation, and enhancing the input context through declarative prompts (such as domain expert knowledge and task description) to guide LLM to conduct effective cross-domain reasoning. This technology provides a solid foundation for the development of multi-modal time series basic model.
3. The performance of Time-LLM in mainstream forecasting tasks always exceeds the performance of the best existing models, especially in scenes with few samples and zero samples. In addition, Time-LLM can achieve higher performance while maintaining excellent model reprogramming efficiency. Greatly release LLM’s untapped potential in time series and other sequential data.
3. Model framework
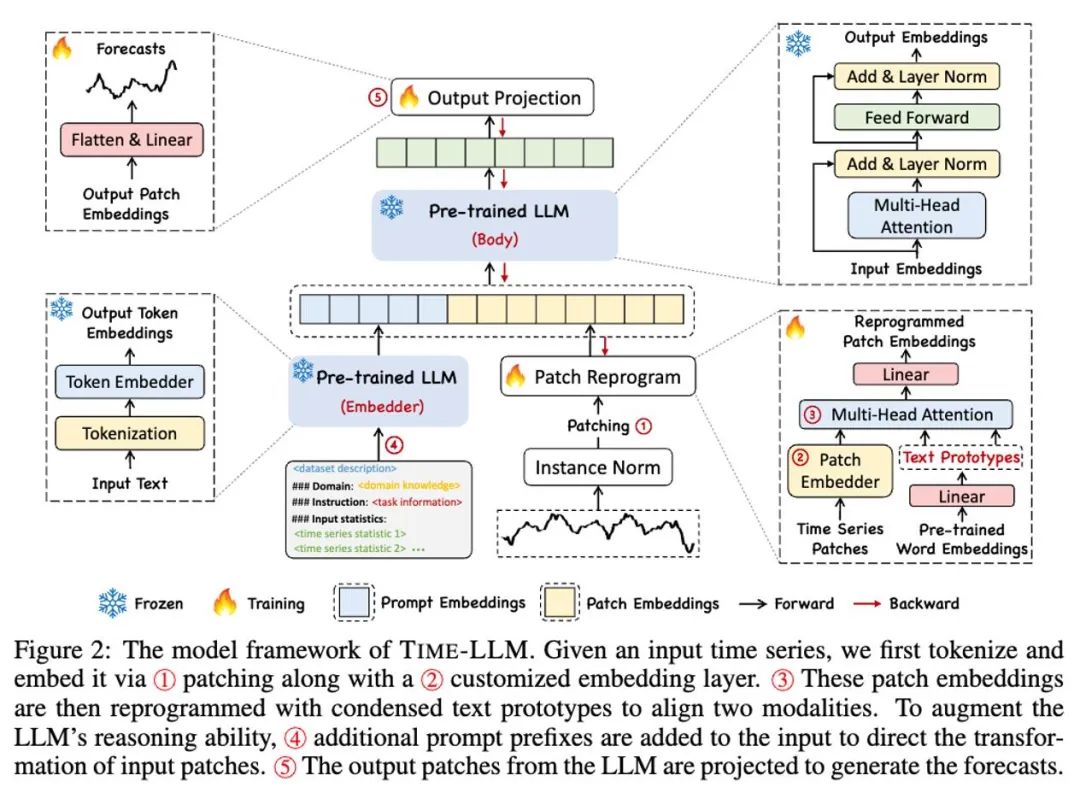
As shown in ① and ② in the model frame diagram above, the input time series data is normalized by RevIN, and then cut into different patch and mapped to the hidden space.
There are significant differences between time series data and text data in expression, and they belong to different modes. Time series can neither be directly edited nor described in natural language, which brings great challenges to prompting)LLM to understand time series. Therefore, we need to align the time series input features to the natural language text domain.
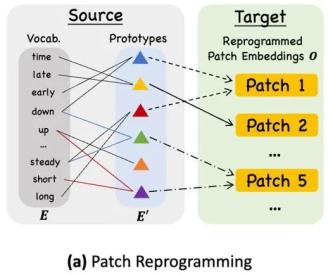
A common method to align different modes is cross-attention, as shown in ③ in the model frame diagram, which only needs to make a cross-attention for the embedding and time sequence input features of all words (in which the time sequence input feature is Query, and the embedding of all words is Key and Value). However, LLM’s inherent vocabulary is very large, so it can’t directly align the time series features to all words effectively, and not all words have aligned semantic relations with time series. In order to solve this problem, this work combines vocabularies linearly to obtain text prototypes, in which the number of text prototypes is much smaller than the original vocabulary, and the combination can be used to represent the changing characteristics of time series data, such as "short rise or slow decline", as shown in the above figure.
In order to fully activate LLM’s ability to specify time-series tasks, this work puts forward the paradigm of prompt prefix, which is a simple and effective method, as shown in the model frame diagram. Recent progress shows that other data patterns, such as images, can be seamlessly integrated into the prefix of prompts, thus making effective reasoning based on these inputs. Inspired by these findings, in order to make their methods directly applicable to real-world time series, the authors put forward an alternative question: Can hints be used as prefix information to enrich the input context and guide the transformation of reprogramming time series patches? This concept is called Prompt-as-Prefix (PaP). In addition, the author also observed that it significantly improved LLM’s adaptability to downstream tasks and supplemented the reprogramming of patches. Generally speaking, it means that some prior information of time series data set is used as prefix prompt in the way of natural language, and it is spliced with aligned time series features to feed to LLM. Can it improve the prediction effect?
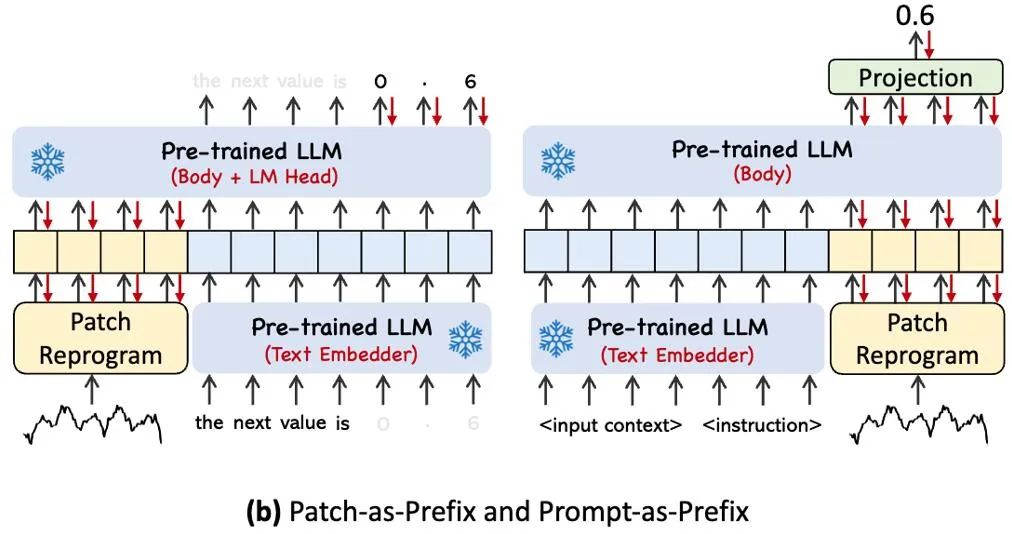
The figure above shows two prompting methods. In Patch-as-Prefix, the language model is prompted to predict the subsequent values in the time series, which are expressed in natural language. This method encounters some constraints: (1) Language models usually show low sensitivity when dealing with high-precision numbers without the assistance of external tools, which brings great challenges to the accurate processing of long-term forecasting tasks; (2) For different language models, complex customized post-processing is needed, because they are pre-trained on different corpora and may use different word segmentation types when generating high-precision numbers. This leads to the prediction expressed in different natural language formats, such as [‘0′,’.’,’ 6′,’ 1′] and [‘0′,’.’,’ 61′], representing 0.61.
In practice, the author identified three key components to construct effective hints: (1) the context of data set; (2) Task instruction, which makes LLM adapt to different downstream tasks; (3) Statistical descriptions, such as trends and time delays, enable LLM to better understand the characteristics of time series data. The following figure shows an example of a prompt.

4. Experimental effect
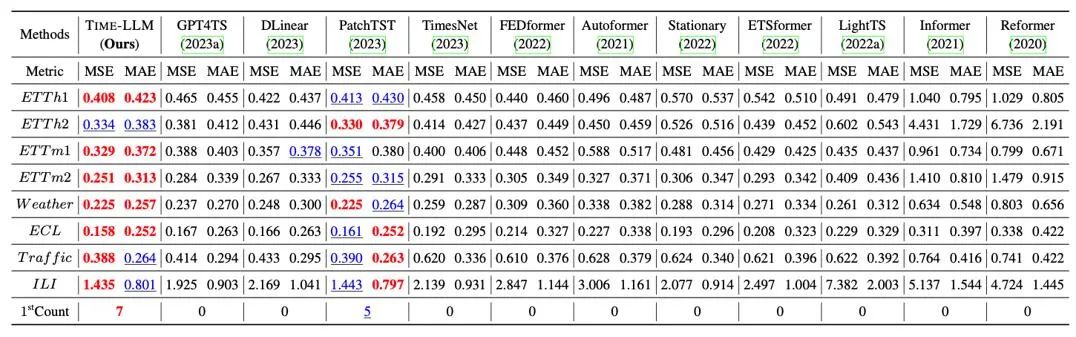
We have conducted a comprehensive test on eight classic public data sets in long-range forecasting. As shown in the following table, the benchmark comparison of Time-LLM is significantly superior to the previous best results in the field. In addition, compared with GPT4TS which directly uses GPT-2, Time-LLM which adopts the idea of reprogramming and prompts as-prefix is also significantly improved, which shows the effectiveness of this method.
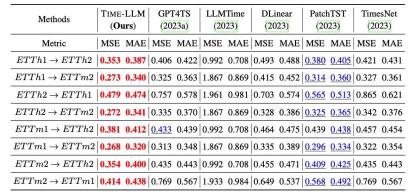
In addition, we evaluated the zero-shot learning ability of reprogrammed LLM within the framework of cross-domain adaptation. Thanks to the reprogramming ability, we fully activated LLM’s prediction ability in cross-domain scenarios. As shown in the following table, Time-LLM also showed extraordinary prediction effect in zero-shot scenarios.
Step 5 summarize
The rapid development of large-scale language models (LLMs) has greatly promoted the progress of artificial intelligence in multimodal scenes, and promoted their wide application in many fields. However, LLMs’s huge parameter scale and its design mainly aimed at natural language processing (NLP) scenarios have brought many challenges to its cross-modal and cross-domain applications. In view of this, we put forward a new idea of reprogramming large model, aiming at realizing the cross-modal interaction between text and sequence data, and this method is widely used to deal with large-scale time series and spatio-temporal data. In this way, we expect LLMs to be like a flexible dancing elephant, which can show its powerful ability in a wider application scenario.
Interested friends are welcome to read the paper (https://arxiv.org/abs/2310.01728) or visit the project page (https://github.com/KimMeen/Time-LLM) for more information.
This project has been fully supported by NextEvo, the AI innovation R&D department under the Intelligent Engine Division of Ant Group, especially thanks to the close cooperation between the language and machine intelligence team and the optimization intelligence team. Under the leadership and guidance of Zhou Jun, Vice President of Intelligent Engine Division, and Lu Xingyu, Head of Intelligent Optimization Team, we have successfully completed this important achievement hand in hand.